Ready to Build High-Performing Image Data?
We’d love the opportunity to answer your queries or learn more about your project
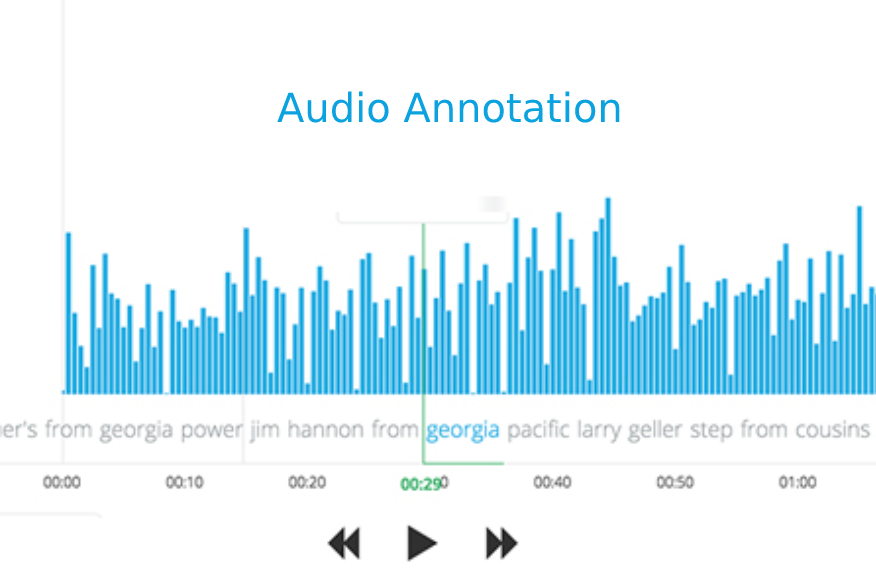

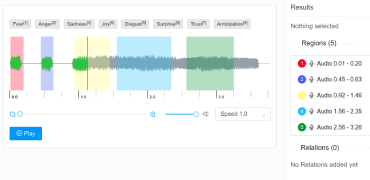
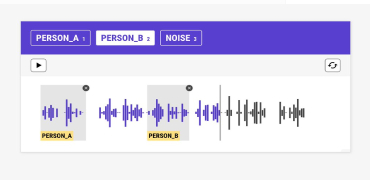
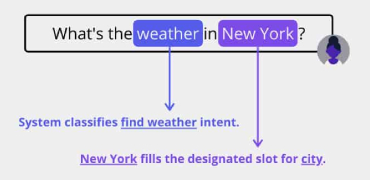
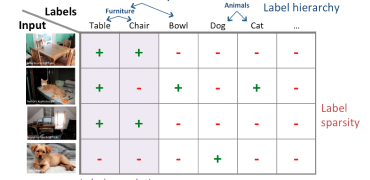
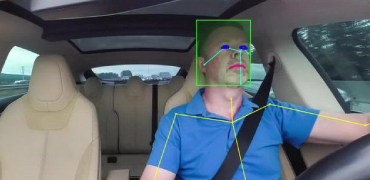

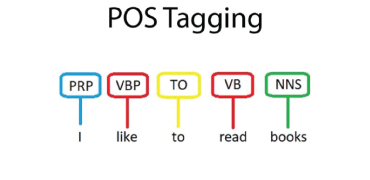
Training machines to understand and correctly interpret the visual world requires a high volume of precisely and accurately labeled training data. Experience, expertise, and access to state-of-the-art tools are crucial as AI programs can function optimally only with concisely labeled data. Data that is customized to your project and specific data training needs. Data that delivers the best cost: quality ratio. That’s where we come in.
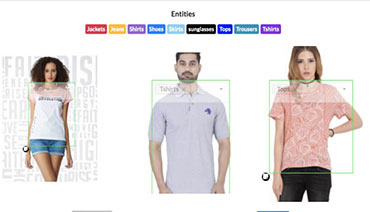
aiTouch is your one-stop solution for all your data-related needs, from bounding boxes, polygons, and landmarking to semantic segmentation and panoptic annotation. We provide high-quality annotated video data for object classification, detection, localization, and segmentation in various use cases. We tailor our specialized portfolio of end-to-end annotation services and solutions to cater to your AI model training needs. Our highly skilled data annotators apply best practices and in-house next-gen video annotation & labeling tools to deliver world-class training data to our clients worldwide. We combine people and technology to create data that powers AI and automation while maintaining complete data security and confidentiality.







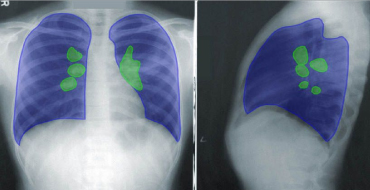





We’d love the opportunity to answer your queries or learn more about your project